.png)
Customer data stored in cloud servers or business applications is typically a big block of information, making it tedious for companies to leverage it. To do so, data teams have to train and produce ML models, use flask or a similar tool to serve the model to make predictions, use Docker to containerize it and host the container on an AWS EC2 instance or also use Kubernetes on GCP to consume the web-service.
This process can take months to complete, and the need to speed up this process becomes increasingly relevant that is why Intercom as an Action can do just that… in minutes. Datagran sends outputs from ML models into Intercom with a simple drag and drop. For example, models including RFM, Recommended Product, Churn analysis, Spark Algorithms, and more.
For Domino’s pizza, building a stack that connected data from their database, into their business application of choice like Intercom, would take months. With Datagran, their team of data scientists is now able to build ML models, and put them into production in minutes, not months, a process that was hurting their efficiency.
“Datagran made it possible to bring ML and the business world together. We're now able to build models in hours, and send the output to Intercom in seconds, which allows our marketing team to leverage data without any delays.”
In a 2021 Customer Support Trends Report done by Intercom, it was found that 73% of support leaders say customer expectations for personalized and fast support are rising, but only 42% are sure they're meeting those expectations. “Customer support is undergoing massive, irreversible change as the old "good enough" support is no longer good enough. Under the weight of the pandemic and outdated tools of the past, overworked support teams are struggling to scale customer support and meet modern customers' demands.” -Intercom
Internally, Intercom is a tool used by our team across different departments. We extract the data that we want to work with from a source like MySQL, then we build a workflow, or how we like to call it, a pipeline, and we apply a processing element like an RFM Operator to identify the users who are most likely to buy again, in a specific period of time, and lastly, we send the outcome to Intercom. Once in Intercom, we build personalized messages specifically for this group of customers. You need to find people who respond positively to your messaging.
Here’s everything you need to know to place the right message in front of the users who are the most likely to buy your products or use your service, by building clustered audiences from your chat and support ticket data sources, and sending the output to Intercom.
Intercom as an Action Tutorial:
Integrate your customer data sources into your Datagran account. Click here to learn how to.

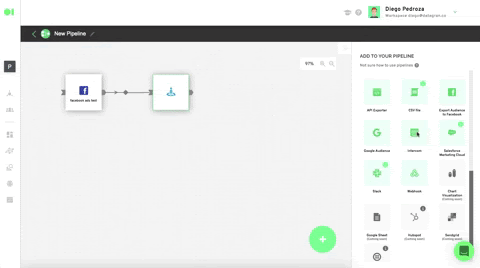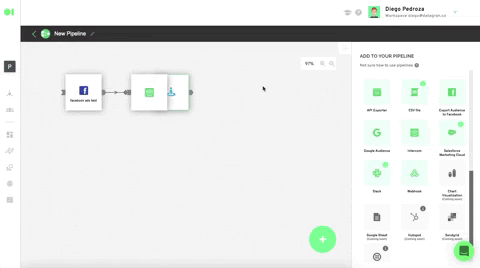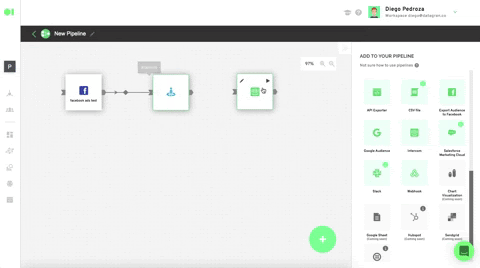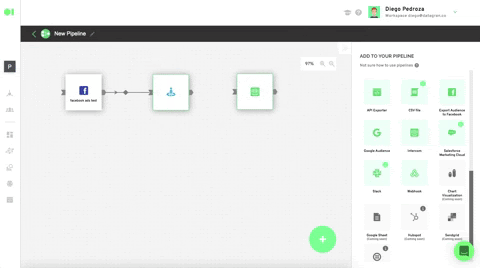
Once your sources are integrated, go to the Pipelines section located on the left hand-side menu to Create a new pipeline. Learn more about Pipelines.
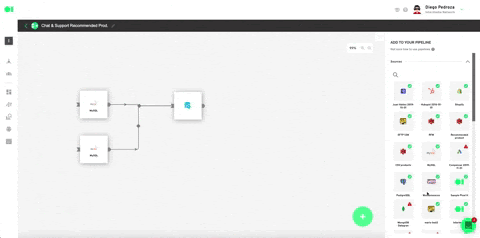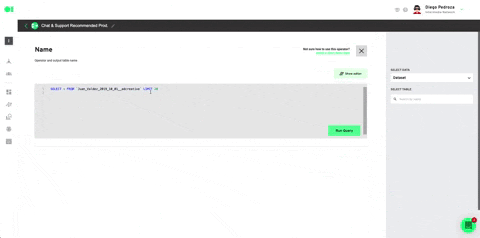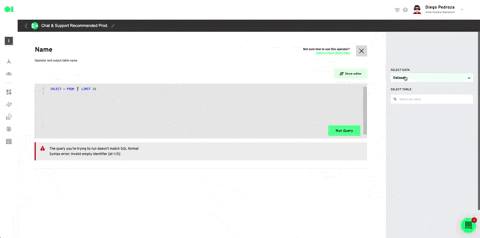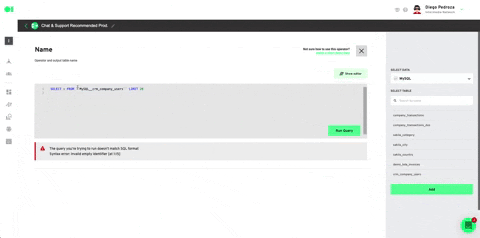
Drag and drop the integrated data sources into the pipelines canvas by locating it from the right hand-side elements menu/data sources. Then, drag and drop the SQL operator to train the dataset and let the machine know which datasets it must work with by hovering over the element and pressing the edit icon. Once the SQL page slides in, choose the first SQL data source and then select the table to be trained. For this example, we will use the Customers table which is located inside the data source, since later on, we’ll add a Spark Clustering algorithm. Continue by clicking Run Query and Save Table. Follow the same process with the second SQL by selecting it from the drop down menu in the SQL page > Select Table.
Train dataset by pressing the play icon.
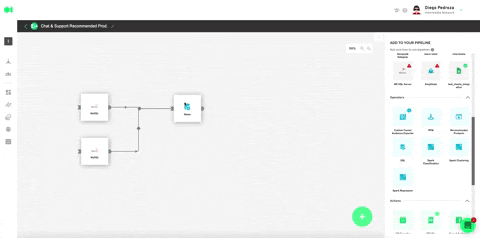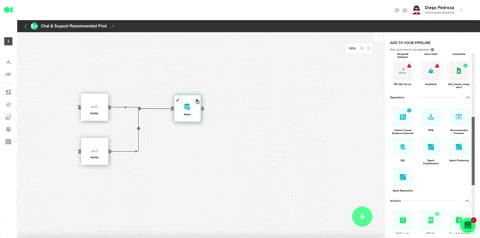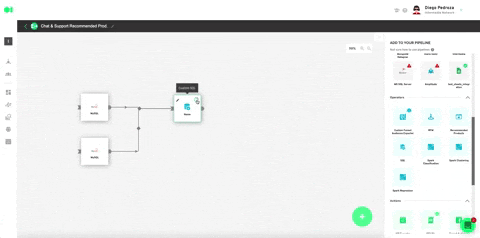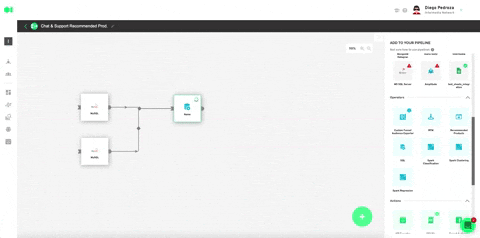
Run a K-means Spark algorithm to cluster your customers by behavioral patterns. From the right -hand-side menu, scroll to operators, drag and drop the Clustering operator into the pipelines canvas and connect the SQL operator to it. Then, configure the algorithm by hovering over the element and pressing the edit icon. To learn more about the Clustering algorithm, read last week’s post.
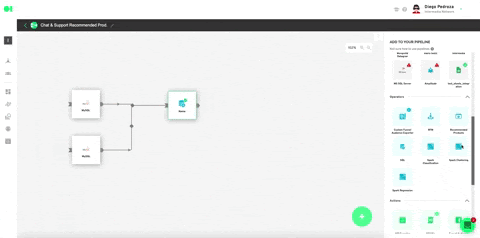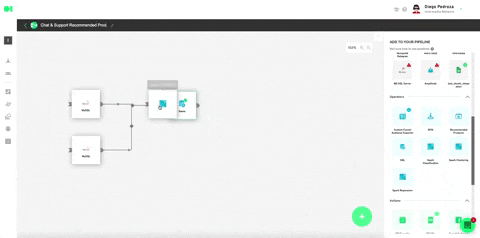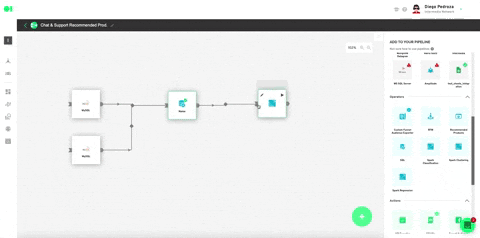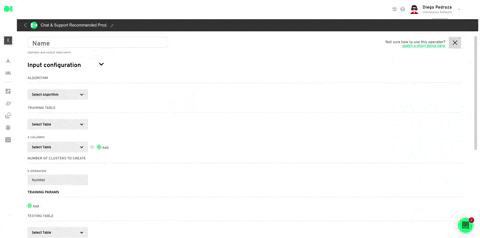
Plug in all the settings like shown below and hit Save.
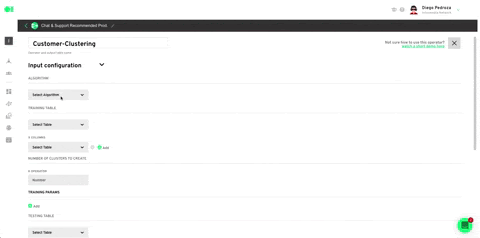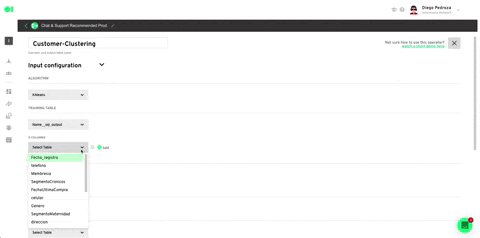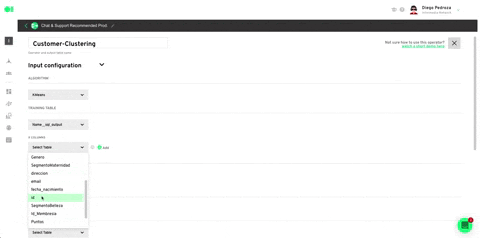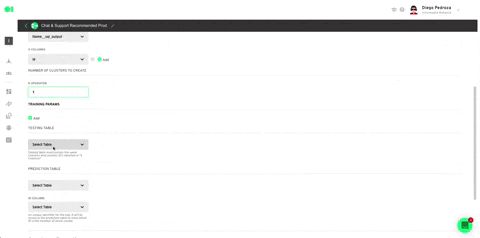
Run the Clustering operator by hovering over the element and pressing the play icon. Once a green checkmark indicating it has successfully completed the process lights up, drag and drop the Intercom action to send your ML model’s results. Head over to the right hand side menu, and scroll to Actions. Locate the Intercom action, drag and drop it into the canvas, connect the Clustering operator to it and press the edit icon to set it up.
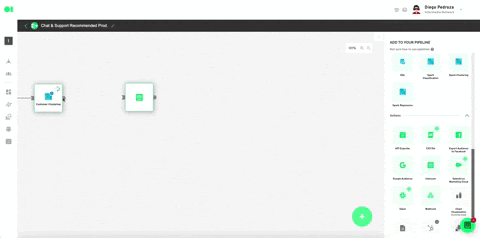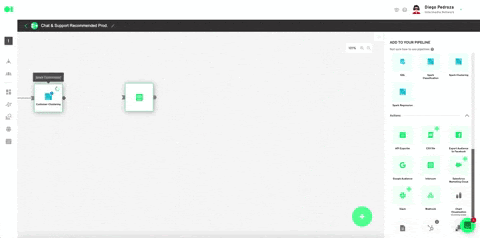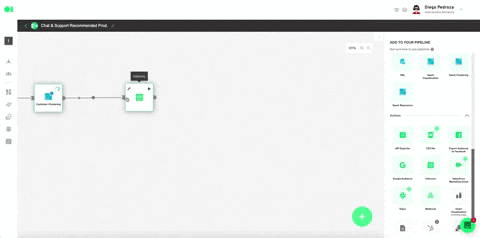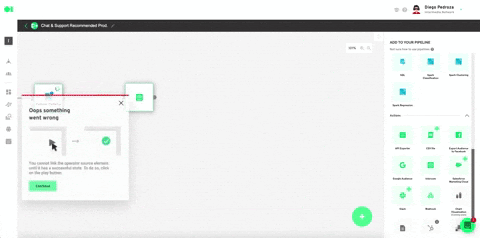
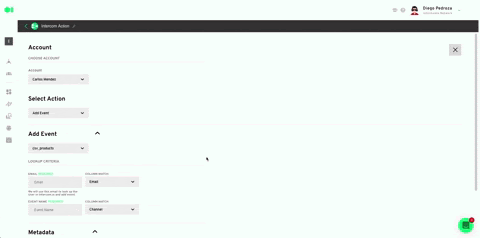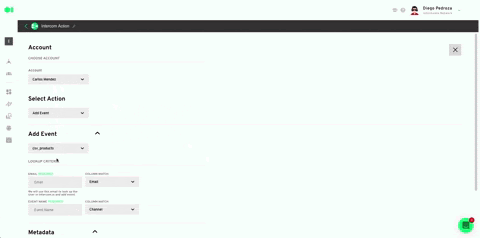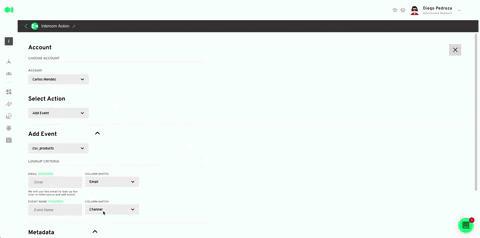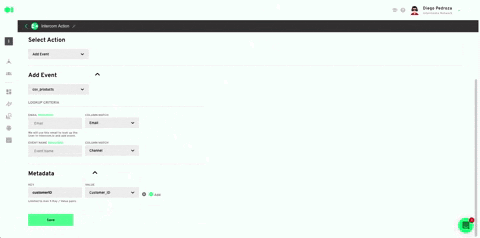
Select your Intercom account or use the 0Auth to connect it. Plug in the rest values like specified below. Hit Save. Once back in the pipelines canvas, run the Intercom element by hovering over it and pressing the play icon. Once it has successfully run, your model’s output will be exported to your Intercom account in the form of a list.
That’s only a few of the many ways you can use Intercom as an Action to make sure you close the loop between your customers and your data. Be sure to try it out with your data sources the next time you need to regain a group of customers who have stopped paying you for services.

.jpg)

