
Handling large amounts of data is increasingly a challenge for companies, more than ever with the huge shifts in the economy happening the last months.
McKinsey & Company stated that 75% of consumers have tried new shopping behavior since COVID-19 started, and they intend to continue it beyond the crisis.
That means more data your company needs to make sense of. As people have changed shopping behaviors, for example, there are more visitors on your store's site, more details about customers who'd never purchased items before, and more sales information from people who purchased new items. You need to make sense of all that data—perhaps to find new customer segments to target, or new items to suggest people add to cart at checkout. So how do you keep the eye on the ball and not lose sight of what your customers need and want?
Clustering can help—especially using machine learning with the pySpark group of clustering algorithms. It mines for patterns inside of large data sets, finds similarities and differences between them, then groups similar data into sets. You can use it for image segmentation, grouping web pages, market segmentation, information retrieval, shopping behavior, fraud detection, and more.
It’s a handy way to make sense of your data and use it to proactively grow your business—but it also comes with some disadvantages. You’ll have to extract and centralize your data, not to mention learning how to use pySpark’s clustering algorithms. And you’ll need to define the number of clusters needed, which can result in a time-consuming process, one that can hurt your company with incorrect conclusions if a statistical or knowledge-backed method is not used in building your data sets. That’s why it often seems easier to just ignore the new data and not put it to work.
There’s a better way: You can automate the whole process with Datagran’s no-code machine learning app. With Datagran, you can centralize multiple data sources in a single place and run ML models with pySpark clustering algorithms (among others) with little to no code, in minutes. Then, you can send the results to your favorite business applications like Intercom, Facebook Ads, Salesforce, and more, or export them into a .CSV file to import into any other app. Or, it can even be sent via API for total flexibility.
Here’s how to start drawing insights from your company’s new data.
Clustering Algorithm Tutorial:
First, integrate the data sources you want to extract data from. Datagran can import data from a wide range of data warehouses and sources, including databases like PostgreSQL, Azure Cosmos DB, Snowflake, and more, along with business software including HubSpot, Shopify, Facebook Ads, Salesforce, Segment, Amplitude, and more.
For this example we will use one MySQL source to pull in our data. Click here to learn how to integrate data sources into your Datagran account.

Then, create a new pipeline—what Datagran calls its workflows—to process your data.

Now, drag and drop the MySQL data source into the pipeline canvas—or the data from any other data source you connected.
Tip: You can also centralize multiple completely different types of data sources like transactional data from Stripe and behavioral data from a CRM, or even data from your website or App by installing our Web Pixel or mobile SDK or by using Segment.
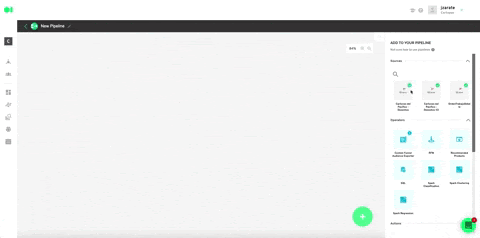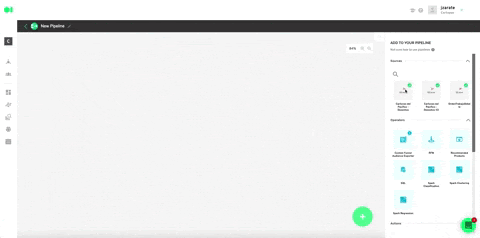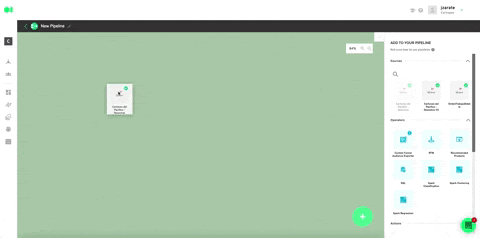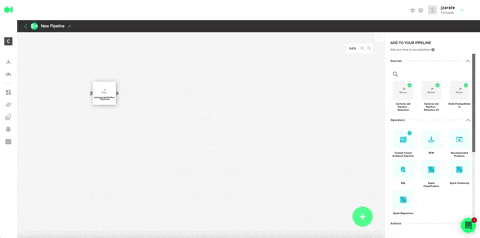
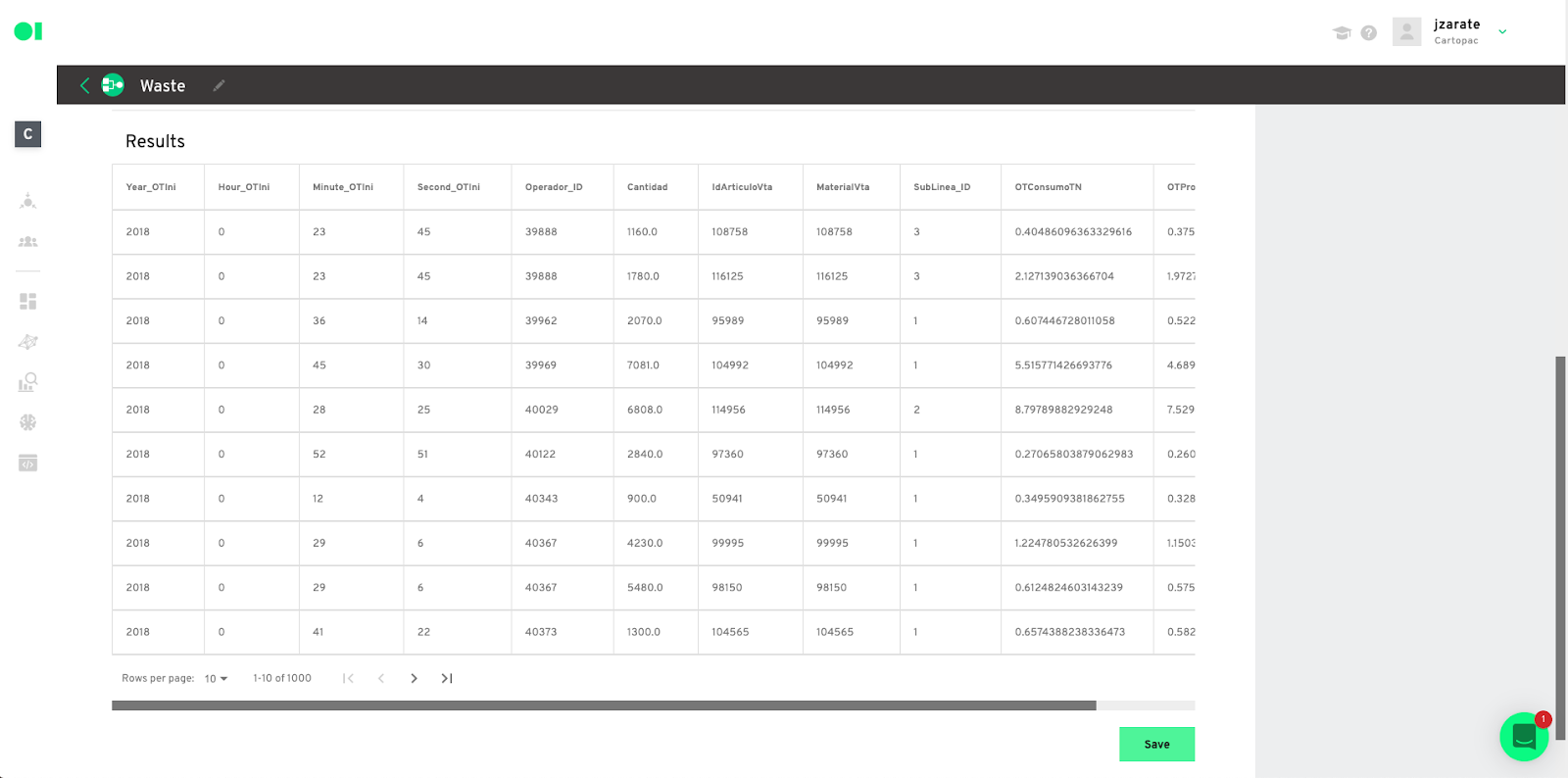
It’s time to get the machine learning working. First, prepare the dataset. For this step, it is necessary to extract the data (columns) to be used from the data source. This will set the model up for Datagran to know exactly the information it needs to work with. To do this, drag and drop an SQL operator into the canvas.
Operators are functions embedded in Datagran’s platform that help you interact with and process data.
Hover over the first operator element and press the edit button. The SQL query editor page will pop-up where you can choose what columns to pull from your data. Copy and paste the query snippet example below and replace each variable to apply to your table’s variables, or press the Show Editor button located on the top right-hand corner to choose the columns without having to add code.
SELECT
Column_1,
Column_2,
Column_3,
Column_4,
Column_n
FROM
Data_source
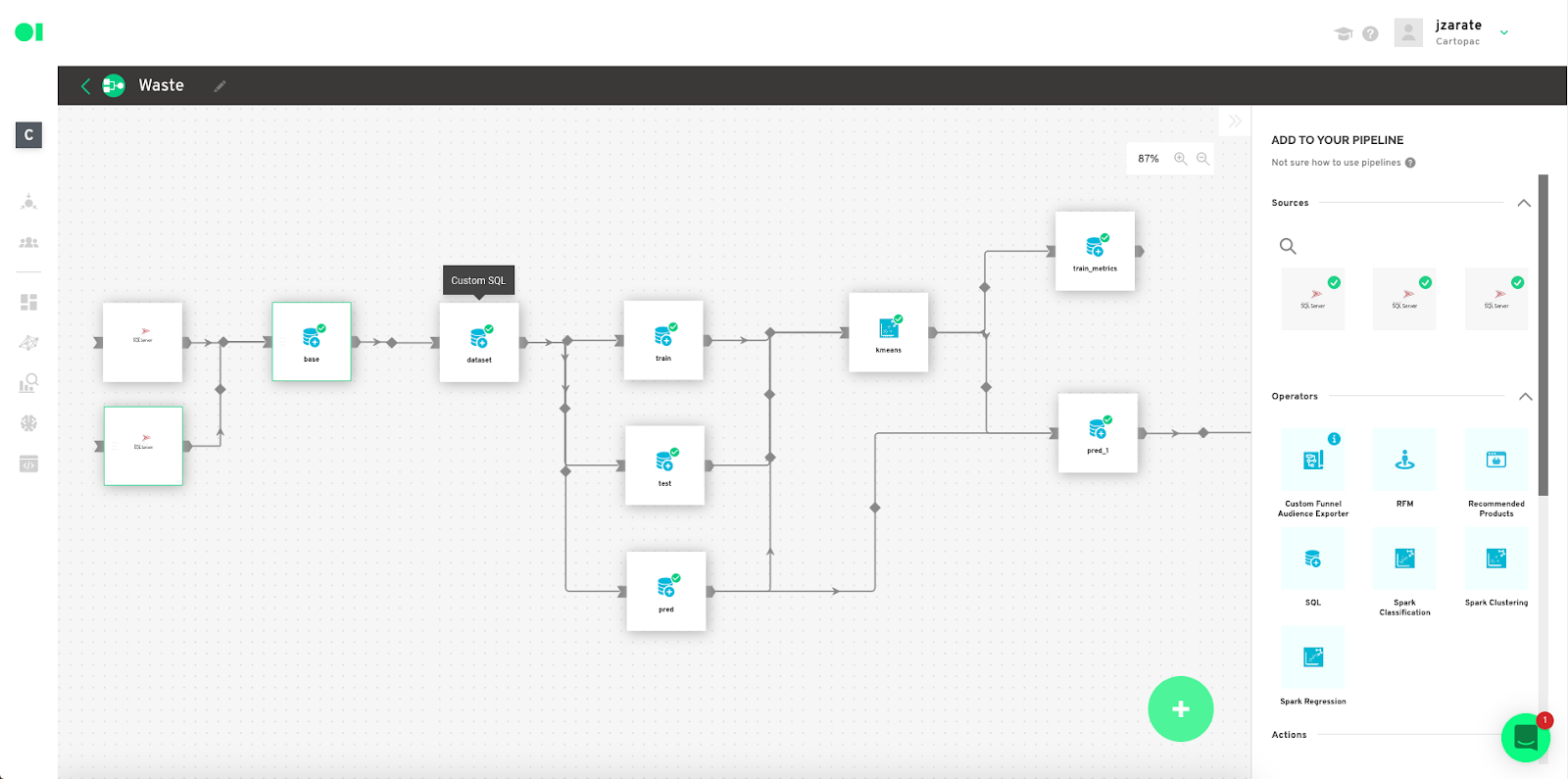
Add your Train, test and predict datasets. To train the model you need a set of data to train the algorithms (train dataset). If you want to evaluate the model, although it is not mandatory, you need a set of test data (test dataset), although it is not mandatory. And finally, the objective is the output of the model, the values you want Datagran to predict. For this, it is necessary to have a dataset for prediction (predict dataset). Start by dragging and dropping an SQL Operator into the canvas.
Tip: We suggest using 80% of the data set for training, and 20% of the data set for testing.
Second, train the dataset.

Copy and paste the query below to train the dataset with your training data. Replace each value with your dataset’s values, paste it into the SQL canvas, and hit Run Query.
SELECT
X0_column,
X1_column,
X2_column,
X3_column,
X4_column,
Xn_column
FROM
Dataset
WHERE RAND() <= 0.8
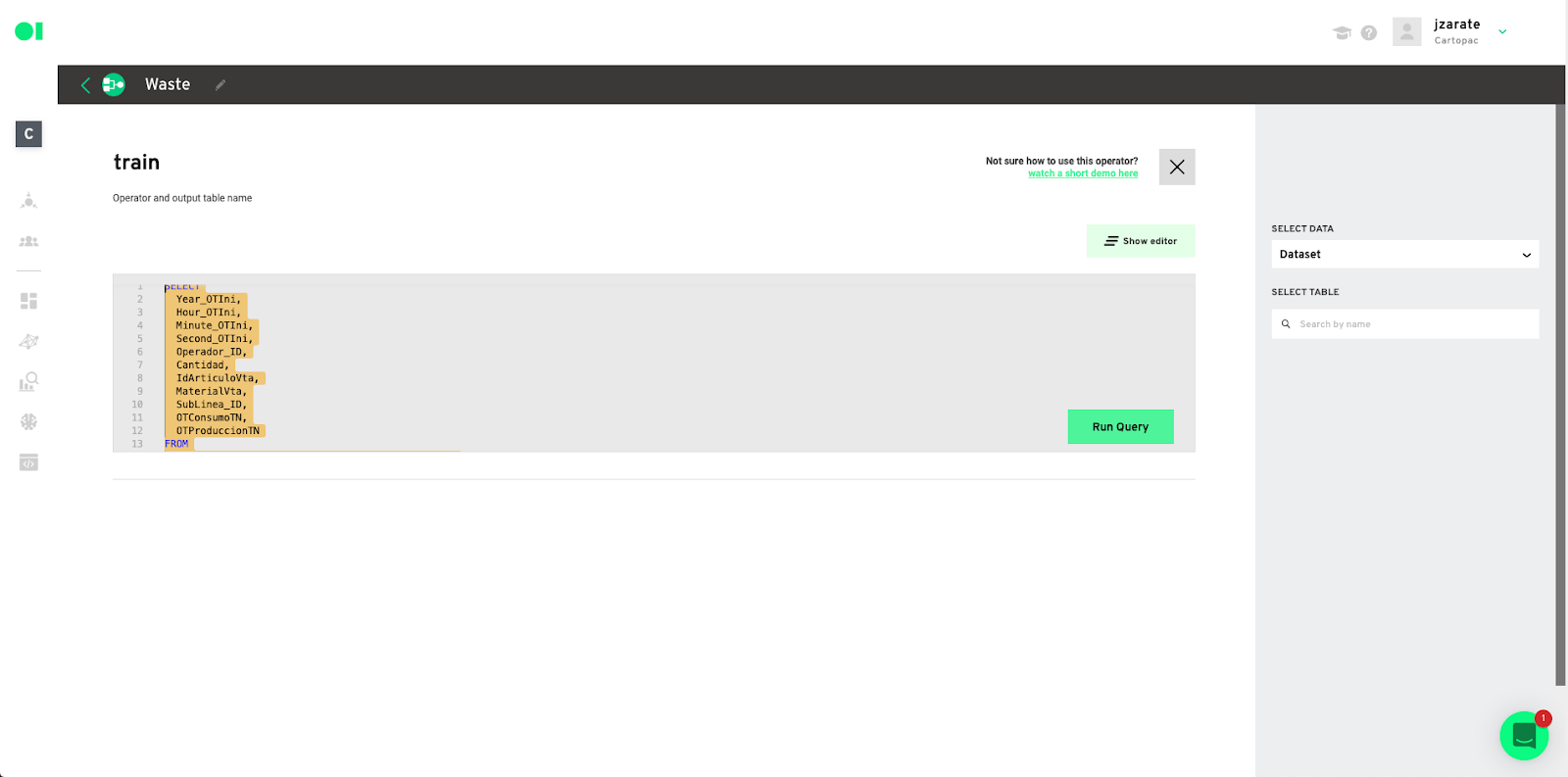
Save the results.

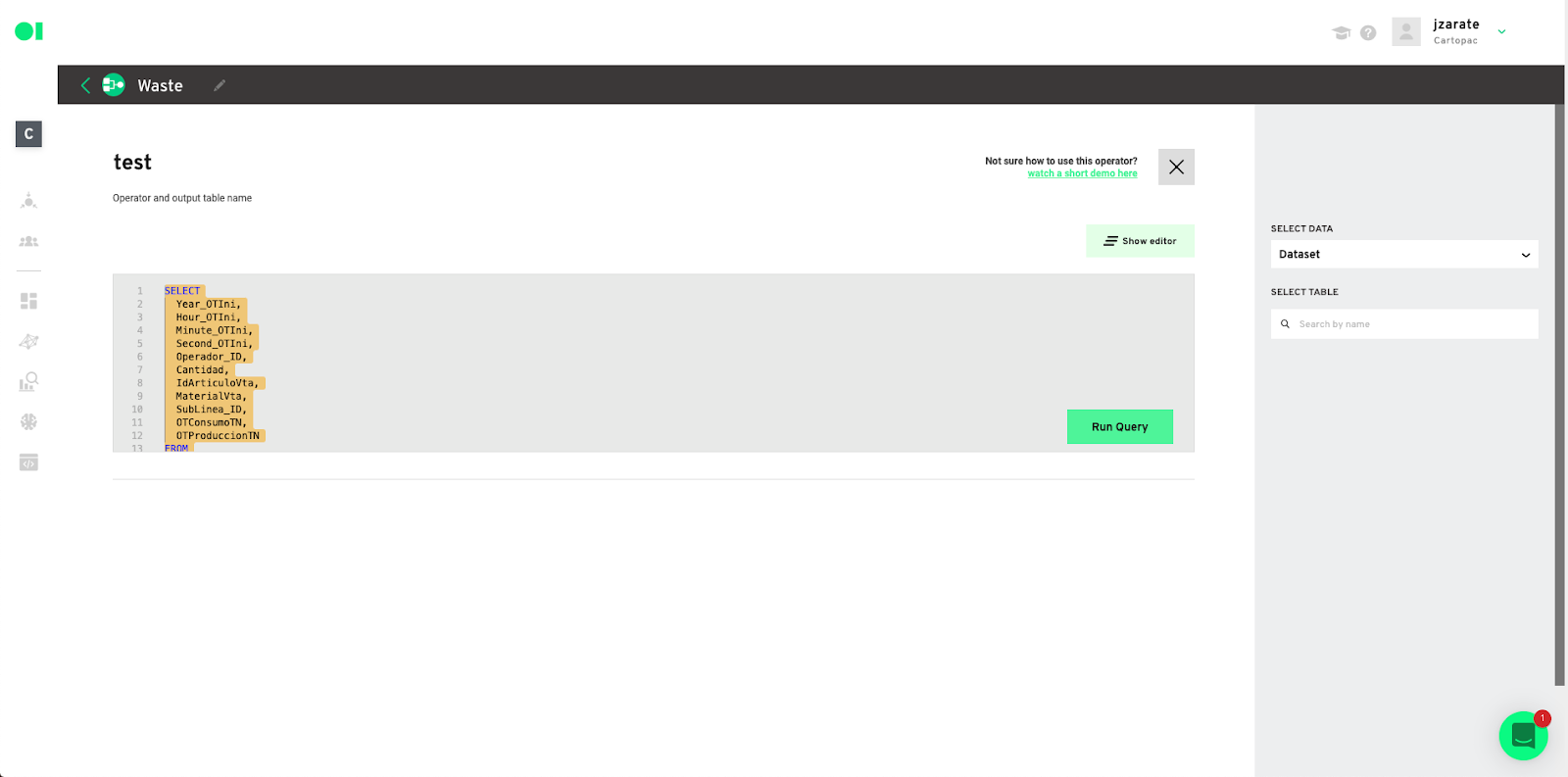
Test dataset. Hover over the Test operator, then copy and paste the below code inside the SQL canvas.
SELECT
X0_column,
X1_column,
X2_column,
X3_column,
X4_column,
Xn_column
FROM
Dataset
WHERE RAND() <= 0.2
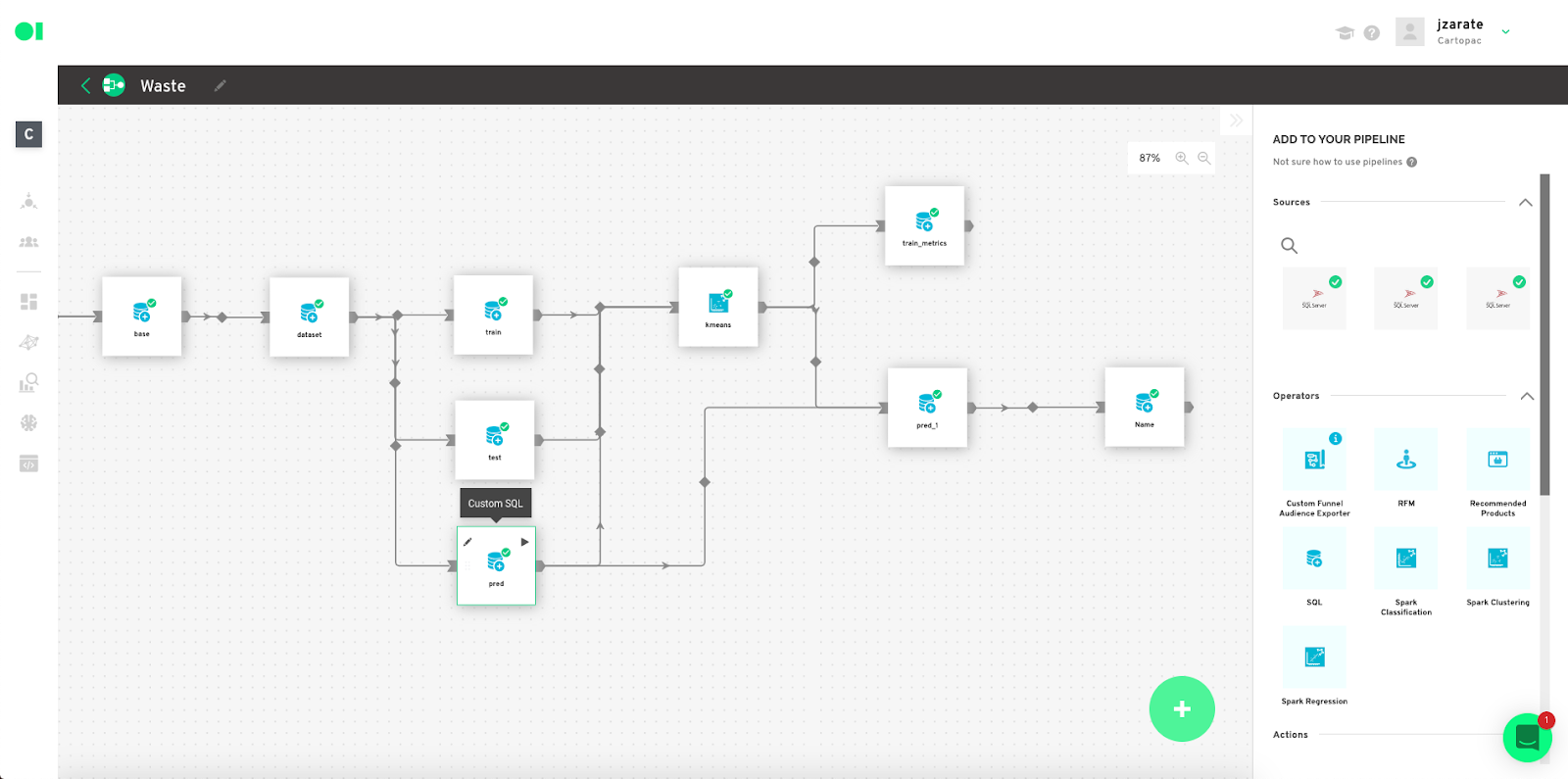
Repeat the process with the last operator and use the below code as template. Make sure you plug in your column values.
SELECT
Customer_ID,
X0_column,
X1_column,
X2_column,
X3_column,
X4_column,
Xn_column
FROM
Dataset
Model configuration– You will now run your first Clustering Operator using one of the available clustering algorithms, such as Gaussian Mixture, Bisecting K-Means or K-Means.
Drag the Clustering Operator located in the right hand side panel, and drop it into the canvas. Connect the three SQL operators into it, then hover over the Clustering element, and press edit.
Input configuration– Choose the K Means algorithm from the “Algorithm” dropdown menu. Continue by selecting one of the tables located in the SQL operators. In this example, we are using the Prediction table “pre_sql_output”. Then, plug in the ID column from your table by selecting the value in the ID column dropdown.

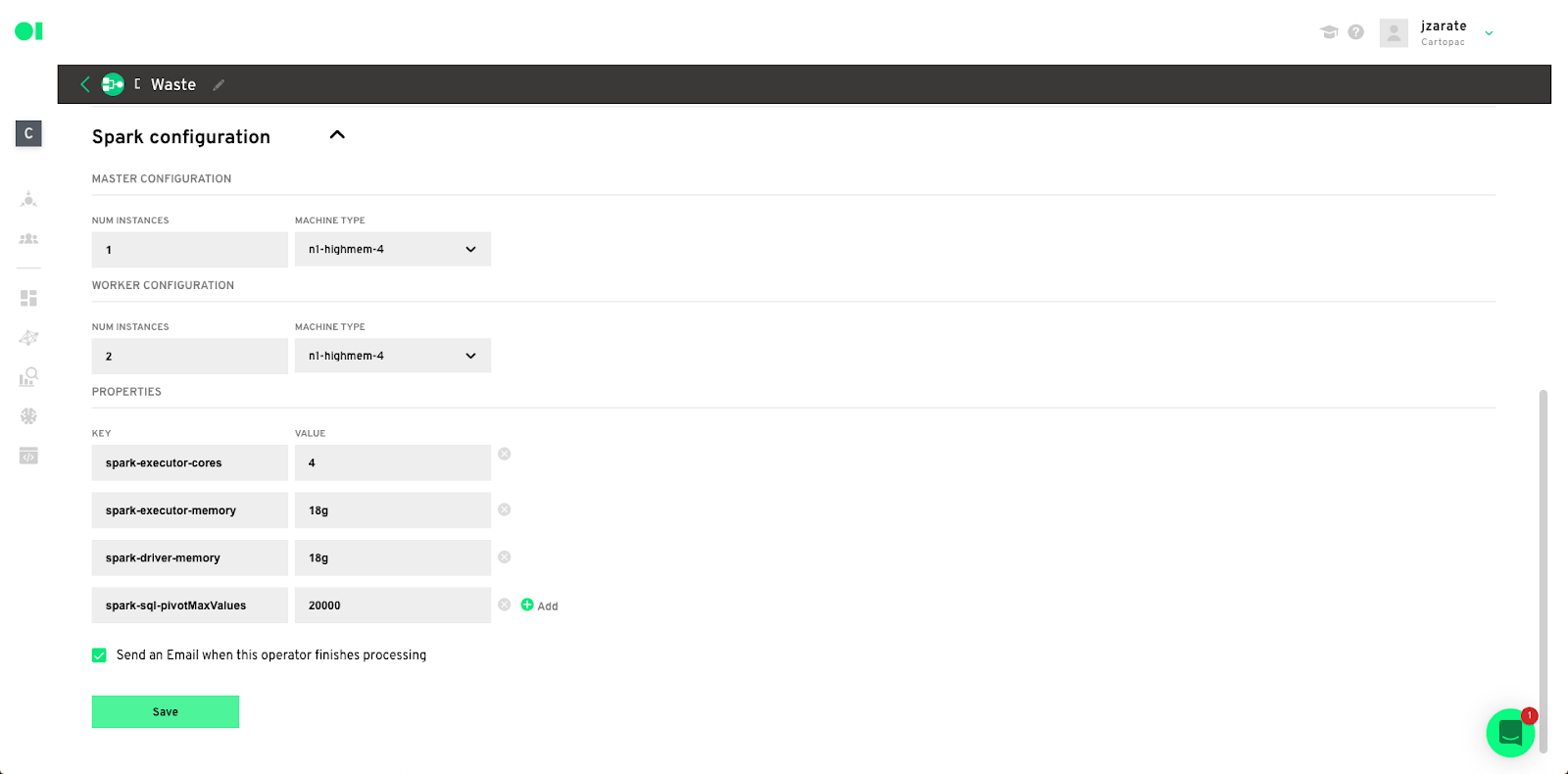
Spark Configuration– Follow the below steps to configure your Spark Algorithm and click Save.
Model output – The result of the model consists of two tables, metrics and predicted values, and this depends on the model you are using since it can have an additional table with the summary.
See train-test metrics evaluation– Drag and drop another SQL operator and connect it to the Clustering element. Hover over the SQL operator and click Edit.
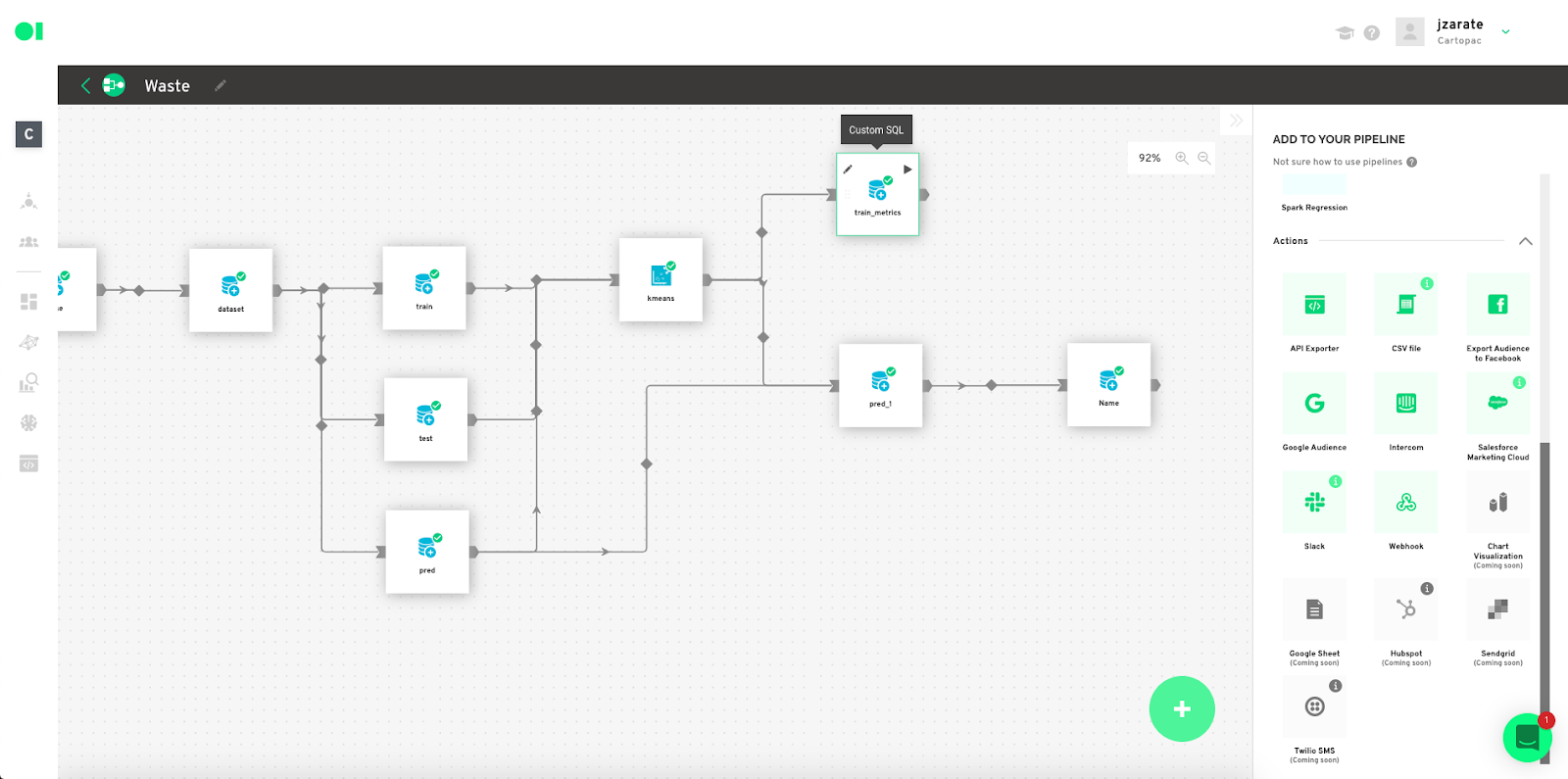
Input the train metrics query– Select the data from the right-hand side panel. Then choose the summary table and drop it into the canvas. Run the query.
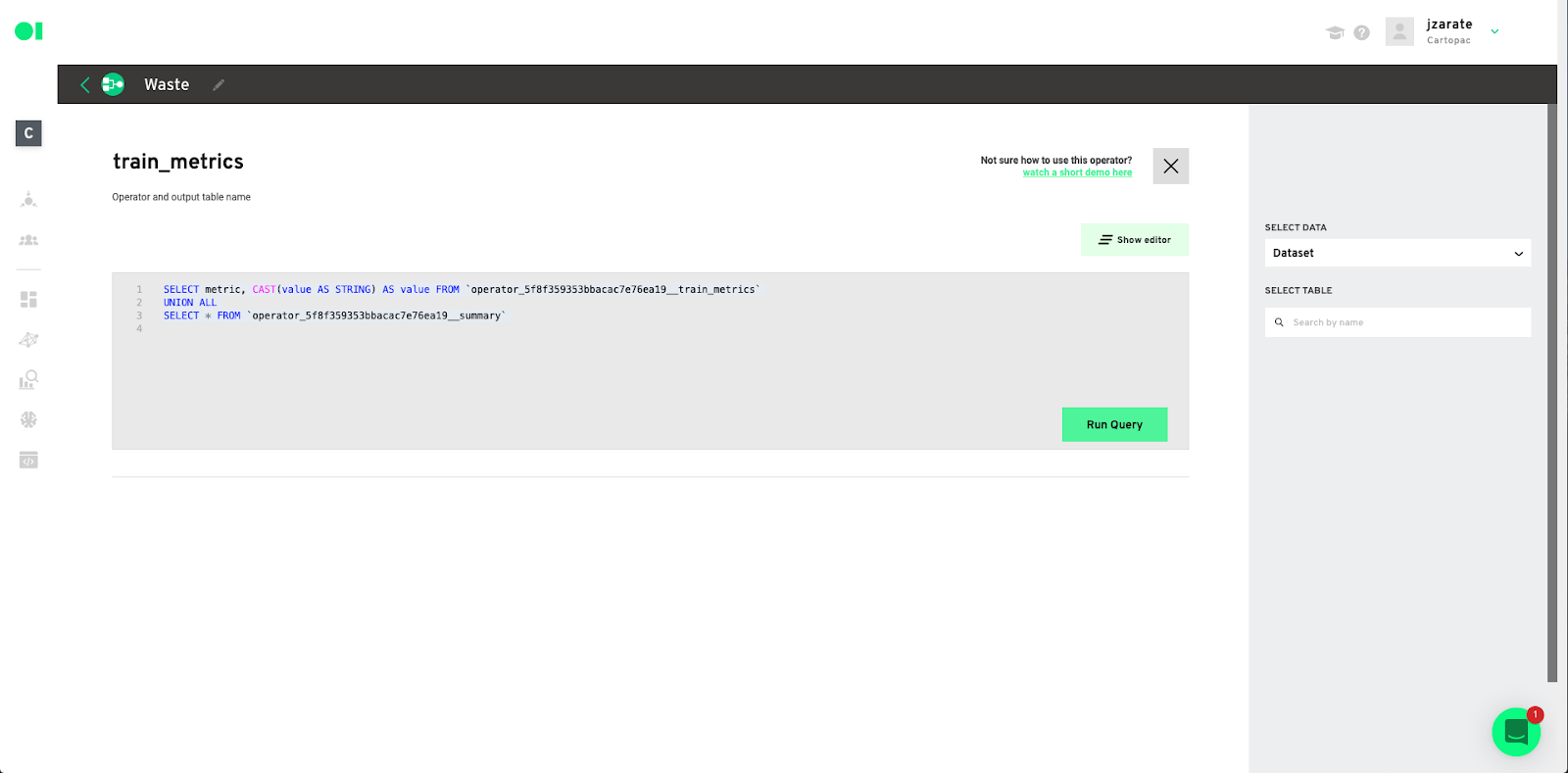
Click Save.
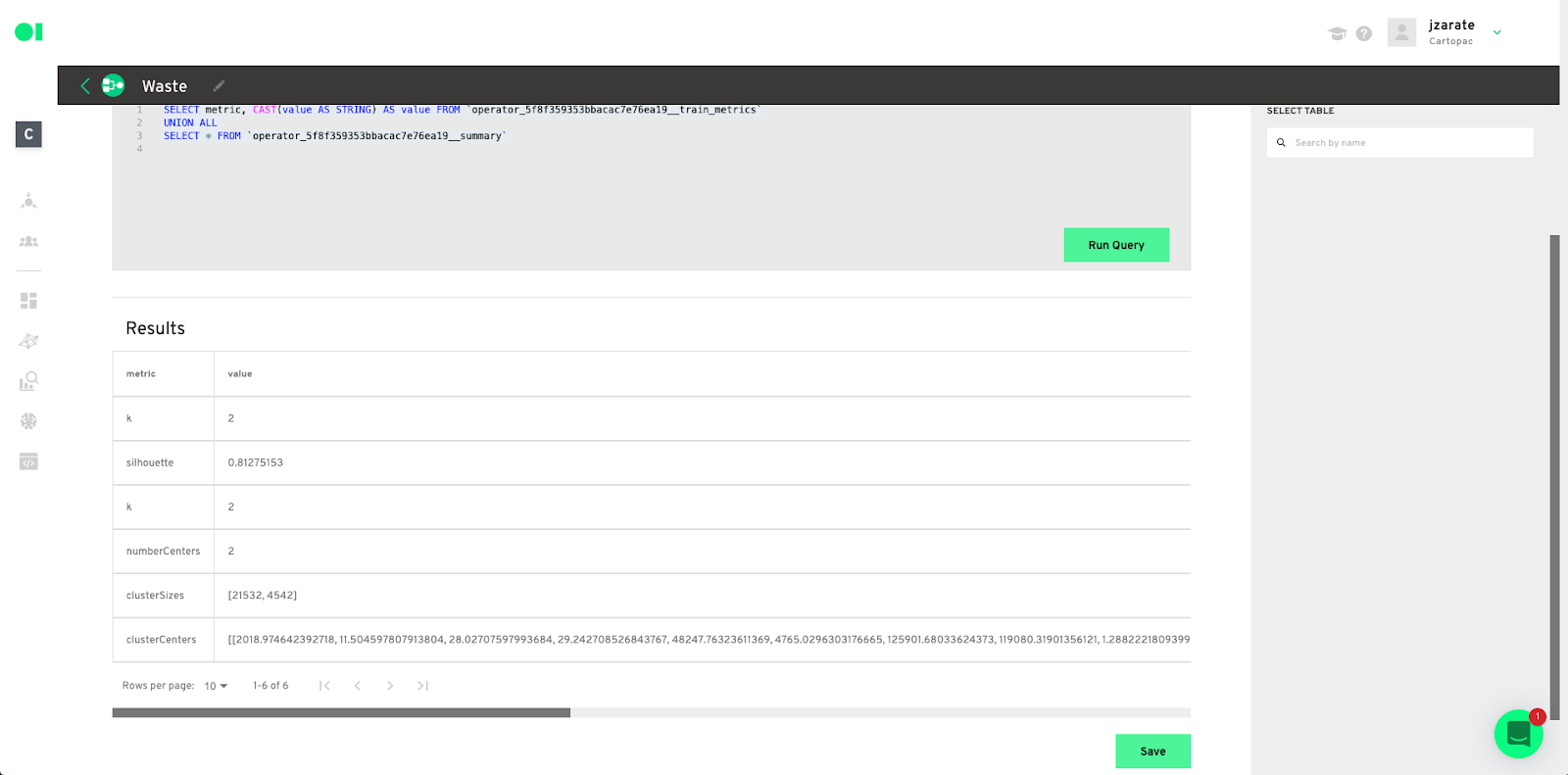
See the prediction metrics evaluation– Drag and drop another SQL operator and connect it to the Clustering element. Hover over the SQL operator and click Edit.

Select the data- Choose the data source to extract information from and then select the table from that source by dragging and dropping it into the canvas. The query canvas will then auto-populate. Run your query and save the results.
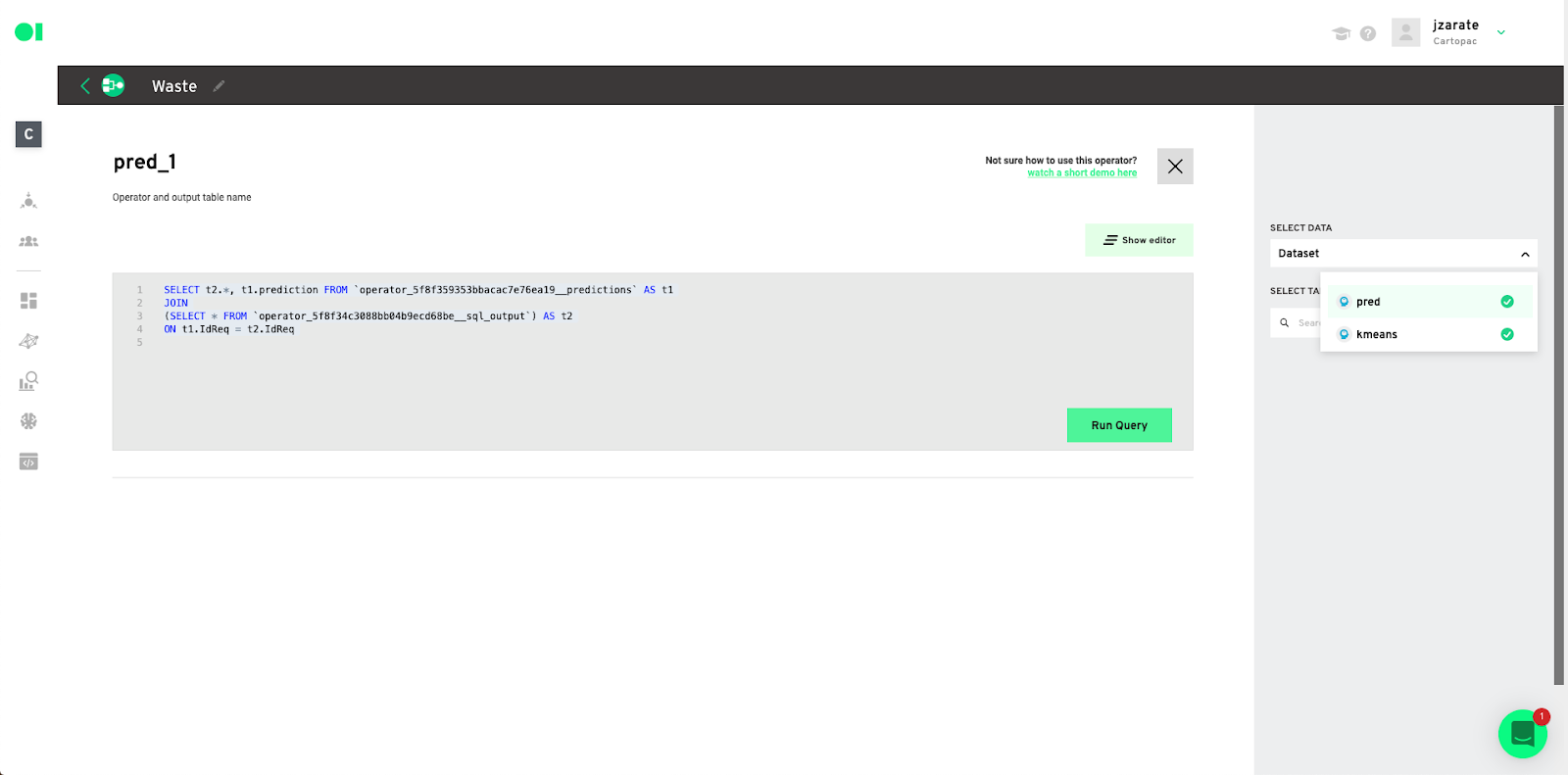
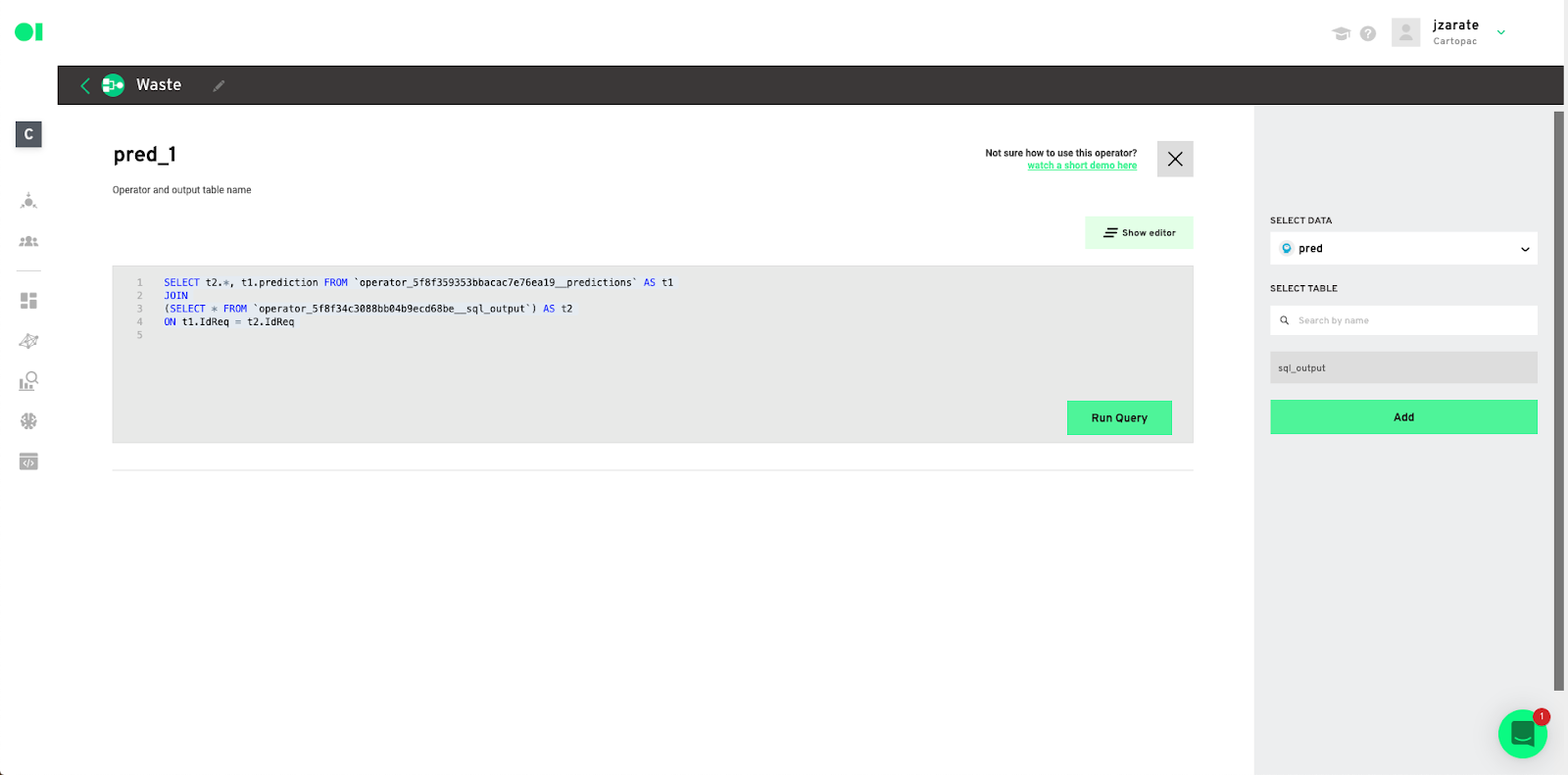
Datagran now has all your data, and knows how to extract the info you need from it. Now it’s time to put your ML model results into production and send them to your other software. Drag and drop an Action element API Exporter into the canvas to do that.
Actions allow you to send the Pipeline’s output into a specific businesses application. One of the main challenges businesses face is how to put ML models into production, fast. To use Actions, simply drag and drop your favorite application, eliminating the need to worry about set up on each specific platform. Standard destinations can be Google Sheets or BigQuery. Some Apps could be Campaign Monitor, Twilio, Facebook Ads or Google Ads. For example, the Mailchimp Action triggers emails based on the results of the previous operators.
Now your ML model results will be exported via API so they can be used by your team as needed. Please note this process may take some time depending on the size of your dataset.
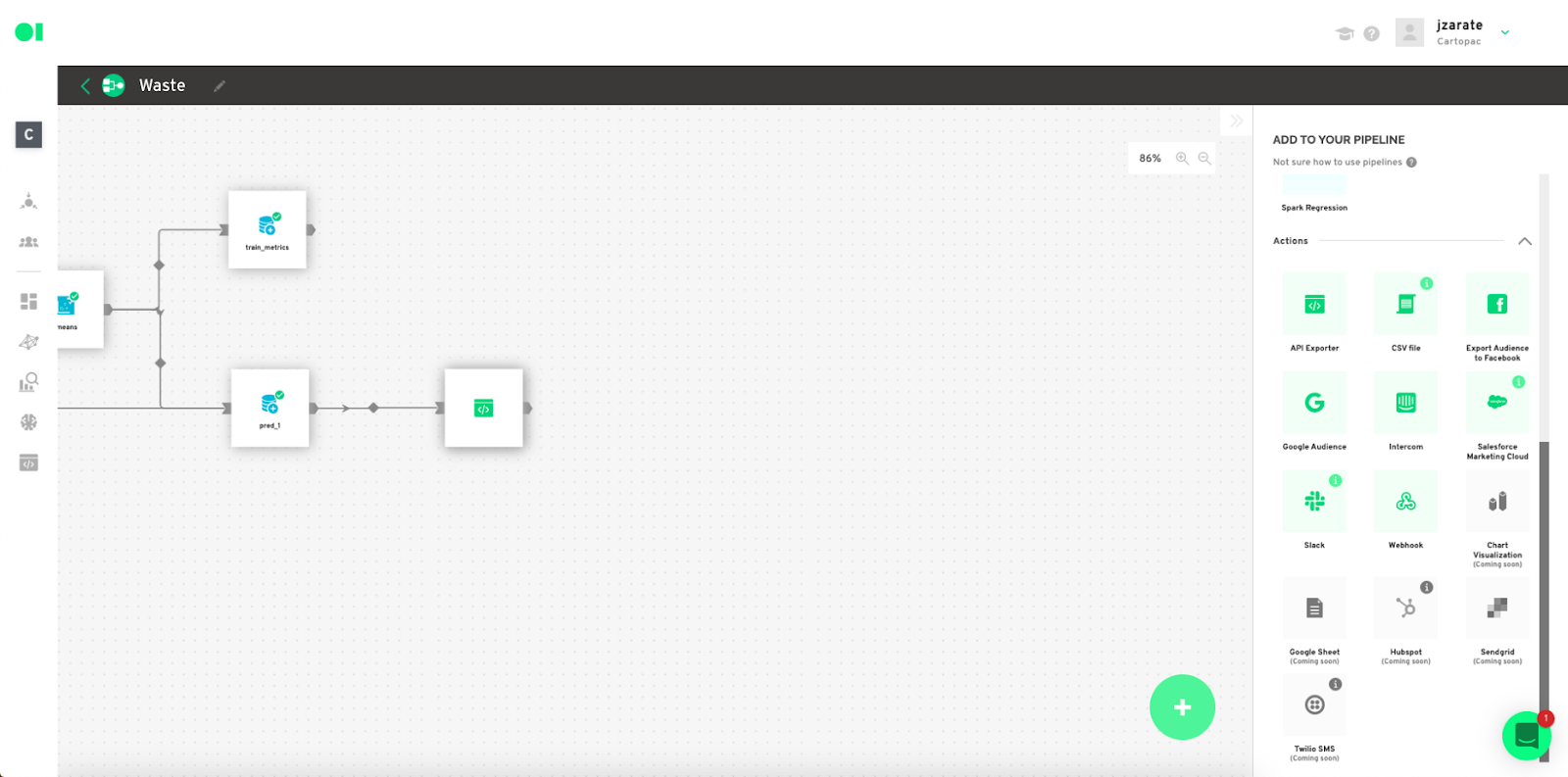
Datagran easily lets you run clustering algorithms with little to no effort, thanks to our pipeline visual editor. You can set up your model, experiment to see the results you get, then connect other data sources and use the same tools to mine that data for insights that can help your business.
Do you need to make higher-level models? Try out our other Spark algorithms for Regression and Classification, and segment your data based on specific attributes like shopping behavior with RFM analysis, Recommended Product analysis, and more. For e-commerce, Datagran is a great solution that helps make your data actionable with ML workflows– read how to turn your Shopify data into Facebook Ads with ML models.

.jpg)

